Granular Dance is a tool that can be trained with motion capture data and then used to generate new dance movement sequences. This tool combines two different components: a deep learning model based on a recurrent adversarial autoencoder architecture, and a sequence blending mechanism that is inspired by granular and concatenative sound synthesis techniques.
Machine Learning Model
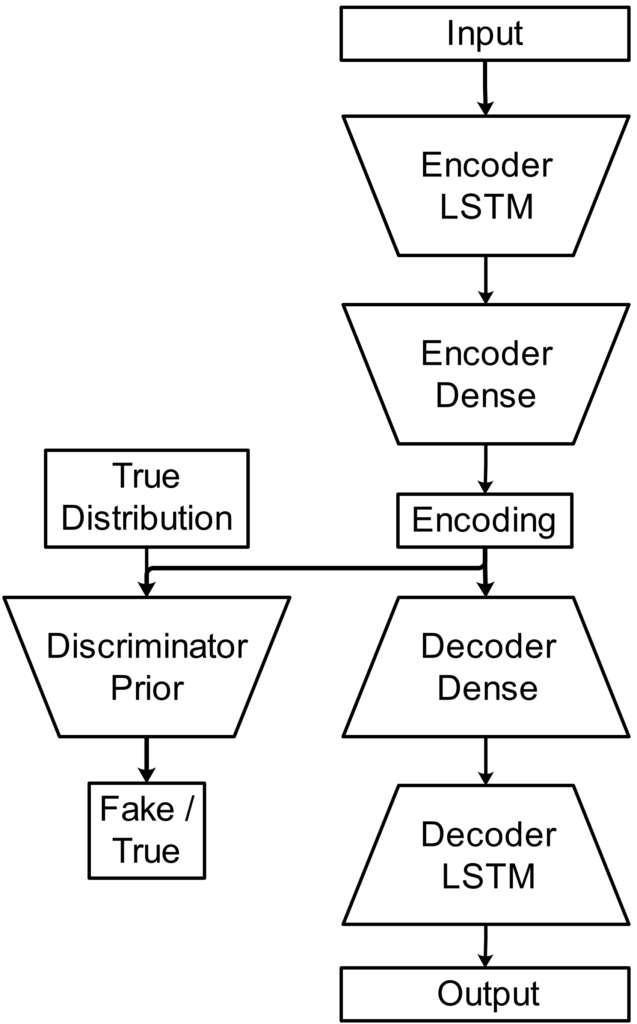
The model consists of an encoder, decoder, and discriminator. The autoencoder part operates on a sequence of poses in which each pose is represented by joint orientations in the form of unit quaternions. The discriminator takes as input a latent encoding of a pose sequence and generates as output an estimate whether the encoding follows a Gaussian prior distribution.
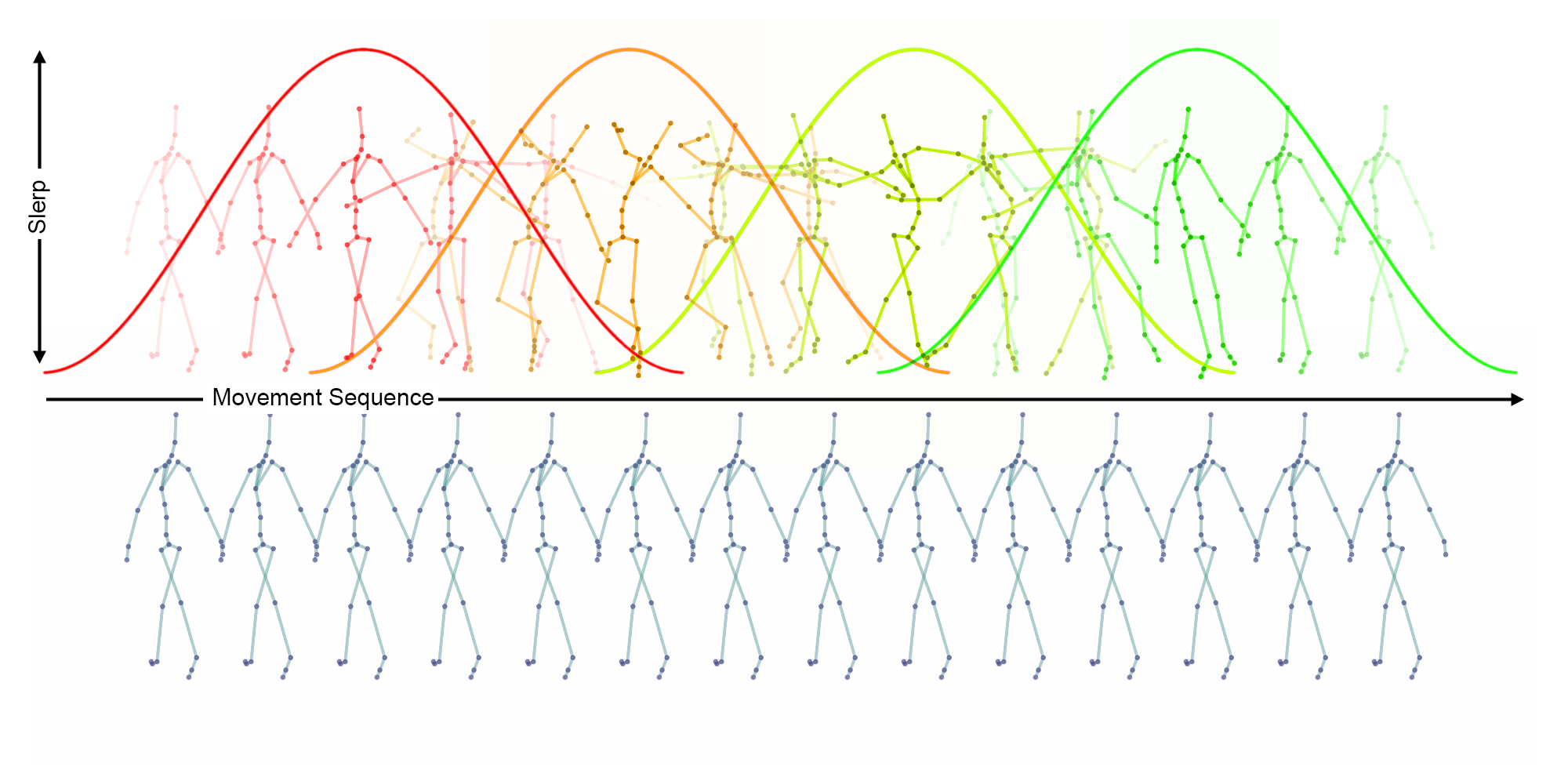
Sequence Blending
The sequence blending mechanism is inspired by two methods from computer music that combine short sound fragments to generate longer sounds: Granular Synthesis and Concatenative Synthesis. For this project, the sequence blending mechanism is used to combine short pose sequences generated by the decoder into longer pose sequences. Similar to Granular Synthesis, a window function is superimposed on the pose sequence which in this case blends the joint orientations of the overlapping pose sequences by spherical linear interpolation.
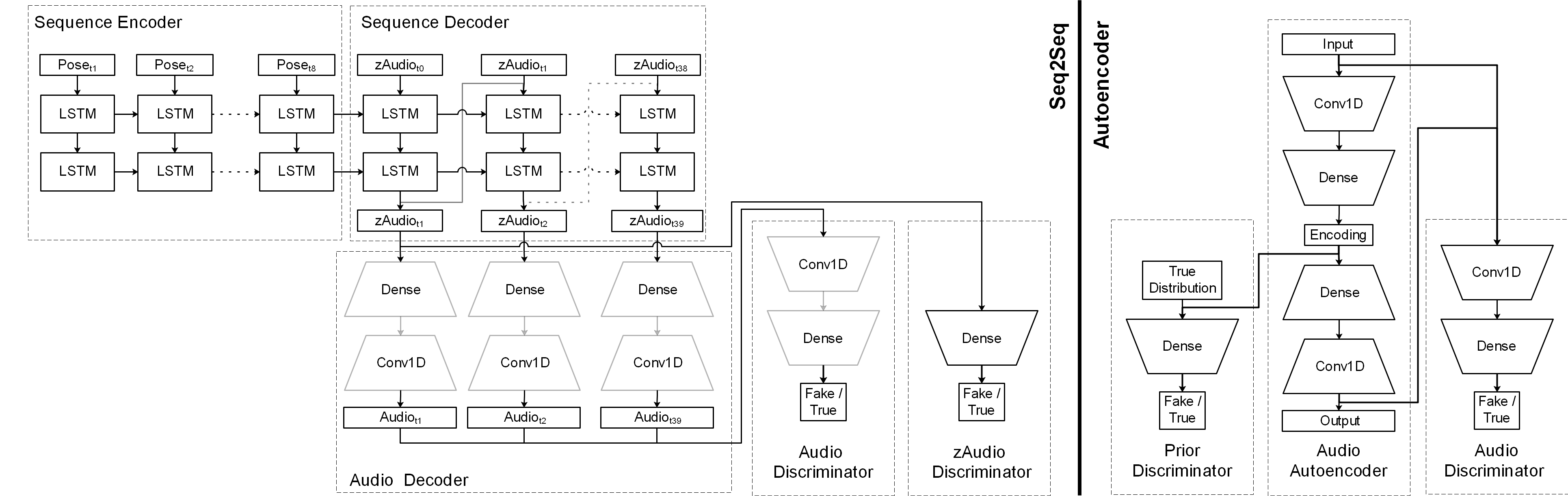
Raw Music from Free Movements (RAMFEM) is a deep learning architecture that translates pose sequences into audio waveforms. The architecture combines a sequence-to-sequence model generating audio encodings and an adversarial autoencoder that generates raw audio from audio encodings. RAMFEM constitutes an attempt to design a digital music instrument by starting from the creative decisions a dancer makes when translating music into movement and then reverse these decisions for the purpose of generating music from movement.
Machine Learning Model
The current architecture of RAMFEM consists of three components: an adversarial autoencoder (AAE), a sequence to sequence transducer (Seq2Seq), and an audio concatenation mechanism.
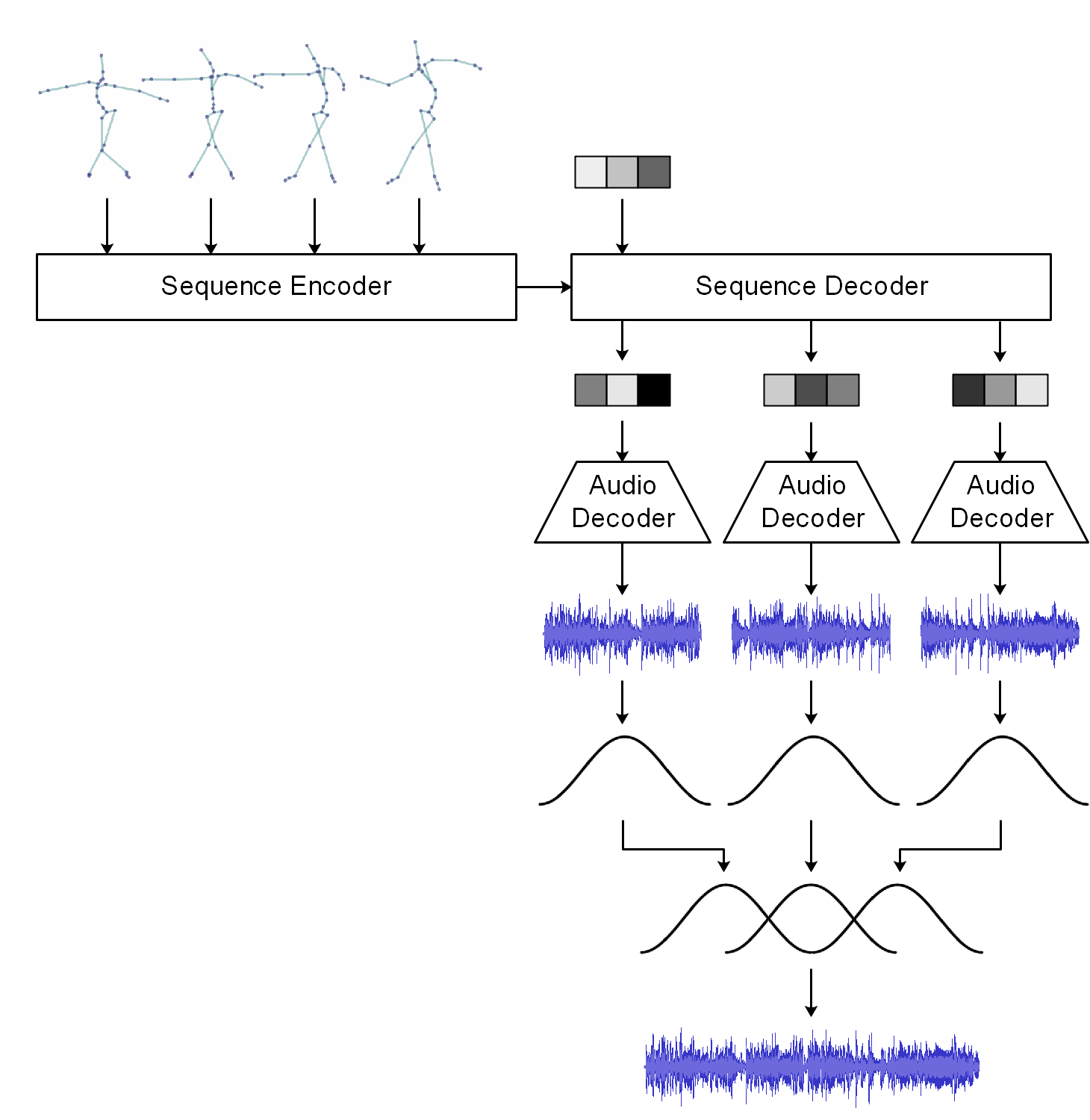
Processing Pipeline
RAMFEM takes as input a short sequence of dance poses and produces as output a sequence of audio windows which are blended together using an amplitude envelope.